以 rCore 为例, 介绍一个操作系统从 RustSBI 开始,从批处理系统到分时多任务系统, 包括地址空间/进程/文件系统的实现,最后实现多线程以及同步互斥的各种机制.
暂时集中在一篇文章里, 以后有需要再分章节记录
运行环境配置
用 Rust 开发操作系统内核源代码, 通过 rustc 交叉编译到riscv64gc-unknown-none-elf (一般情况下是x86_64-unknown-linux-gnu), 通过 rust-objcopy提取出 bin, 然后放到 qemu-system-riscv64 模拟器进行模拟,大概是这么个工具链.
QEMU 最好装 7.0.0 版本的,从源码编译安装的话需要注意一下依赖, 部分发行版的依赖可以在
Arch Linux 仓库里是 QEMU 9, 需要修改一下 RustSBI 的版本.注意如果你想直接 downgrade 到 7.0.0的话可能会需要连带降级一些非常核心的软件包, 非常不建议尝试.有需要也可以自行寻找依赖包然后从源代码编译,但是有一些接口变动可能会导致编译失败, 所以最佳方案还是替换RustSBI 版本, 这里不再赘述.
根据 OSTEP 的说法, 操作系统的主要三个任务部分在于:虚拟化, 并发,可持久化
- 虚拟化主要表现在:
- 对内存的抽象: 每个进程有自己的虚拟地址空间,造成每个进程独占一个主存的假象(学过 CSAPP 可以回忆一下第九章,博客还在补)
- 对 CPU 的虚拟化: 主要表现在操作系统内核对各个任务的调度,使得每个任务产生独占 CPU 的假象(这就是一种并发)
- 对外设设备的虚拟化等等
- 并发主要表现在:
- 进程概念的抽象和实现, 进程间通信
- 多线程的实现
- 可持久化主要涉及文件系统
而形式上, 操作系统是一个二进制文件或二进制文件镜像, 被 bootloader加载进内存的特定位置, 驻留在内存中的特定代码,这些代码负责一些加载应用程序(简单来说就是把可执行文件加载到内存),管理资源(设备/文件)并提供访问的任务,这些任务以系统调用(syscall)的形式暴露给应用程序,只是系统调用函数比较敏感特殊, 下面会仔细介绍.
那么我们的任务就比较明确了:
- 先设计一个基本的能把应用程序加载到内存的功能(当然因为现在内核没有任何调度能力也没有让应用程序启动其他应用程序的必要(这依赖进程的实现),所以我们暂时不需要设计
execve系统调用) - 实现标准输出能力 (实际上标准输出就是调用系统调用
write,目标为1(标准输入)) - 实现退出程序的能力 (
exit系统调用)
我们不能再依赖的
在 execve 系统调用, loader 加载可执行文件到内存,_start 执行一些初始化工作, 调用__libc_start_main, 最后调用用户的 main函数
但这是一个用户应用程序的启动流程,我们写操作系统的肯定是没有这些东西了: execve是操作系统提供的系统调用, 我们要在很久后才能实现, loader本身就是操作系统的代码, _start 位于 ctrl.o 而__lib_start_main 位于 libc.so,这一串东西里面我们一个有的都没有, 甚至更坏的是, 我们不能再依赖 Rust 的std crate, 因为我们处于裸机平台.
有条件要上,没有条件创造条件也要上。—— 王进喜, 1963
对于 Rust std 的缺失, 我们可以用 core 代替,它包含了 Rust 的相当一部分核心机制, 我们将会在后面见到core::slice::from_raw_parts 的重要作用;
对于操作系统的执行入口我们暂且按下不表,只需要知道我们需要显式告诉编译器我们暂时没有 main 函数
1 |
当然, 我们还需要提供 panic 的语义项, 详见
操作系统的入口在哪?
这里详细介绍一下操作系统(甚至是计算机)的启动流程:
- UEFI 固件进行自检, 看看有没有什么坏了, 没什么好说的
- UEFI 读取引导设备列表(比如装系统时的 liveCD, 或者硬盘, 读取 MBR(BIOS) 或 EFI 分区 (UEFI), 将 bootloader (引导加载程序)加载到内存中并执行(例如你看到的 grub 页面)
- Bootloader 读取自身配置文件, 列出可选的操作系统, 然后加载内核. 对于Linux 来讲, 就是执行
linux /boot/vmlinuz ...加载内核,执行initrd初始化initramfs, 然后使用 UEFI机制跳转到操作系统内核的入口点(其实还会释放自身) - 操作系统执行一些必要的任务初始化自己, 即我们通常理解的开机(挂载目录,启动守护进程). 对于 Linux 来说, 入口点在
arch/x86/boot/header.S中的_start位置
当然这是一个相当简化过的流程,我们尽可能不偏离介绍操作系统的核心部分.
所以我们知道我们的操作系统入口在 _start 位置,但是具体要怎么做? 我们要写汇编吗? 不,我们可以通过链接器脚本来安排内存空间布局,我们要自己确定 .text 段 .data 段等的地址,前后布局, 对齐等. 链接器脚本的语法不要求掌握,但要知道他是用来做什么的.
显然 _start 应该在 .text 段的初始位置.ENTRY(_start) 可以规定入口点. 但是这些东西具体的位置在哪呢?我们知道怎样安排 .text .rodata.data .bss 的相对位置,但不知道绝对位置(也就是说我们缺一个 BASE_ADDRESS).回顾计算器的启动流程, 我们发现是 bootloader 跳转到操作系统入口的.而在我们的实验中, RustSBI 起到 bootloader 的作用,而它要求我们把入口点设在 0x80200000. (当然 RustSBI还提供了更多的操作机器的接口)
我们还需要初始化栈空间布局, 在 entry.asm 中初始化栈指针,然后让 _start 直接调用 rust_main 函数,这也就是我们通常理解下的 main 函数了, 则我们写的操作系统的main.rs 大概是这样的:
1 |
|
#[no_mangle] 用于函数名不被混淆, 否则链接器会找不到rust_main. 链接器脚本 linker.ld 提供给编译器,不需要再代码中体现.
理论上, 我们现在就有了一个可以在 RISC-V架构上的裸机环境运行的纯粹的操作系统, 没有任何用, 我们甚至不知道怎么写Hello World(因为暂时还没 println! 宏),甚至这个操作系统不能够正常退出!
1 | 编译生成ELF格式的执行文件 |
实现正常退出
从这里开始, 我们就要提供系统调用.也许你看到这篇文章时我已经补完了 CSAPP 第八章的博客,不然你就只能自己翻书了解一下内核态与用户态以及 Trap 是什么了.我开玩笑的, 因为这里面有一些术语不通用.
指令执行的环境有三种
- 最高权限的机器级别(M), RustSBI 在这个环境下
- 次高权限的, 内核态或特权级别(Kernel Mode 或 Supervisor Mode),操作系统内核在这个环境下
- 用户态(U), 用户程序所在位置
操作系统要做的就是封装, 管理和组织起来 RustSBI 提供的及其底层的接口为syscall, 暴露给用户程序(当然具体实现上 syscall 不一定全都是在调用RustSBI, 也有可能直接在内核态操作内存, 总之通过 syscall trap进内核态是操作系统从驻留内存静止到真正被执行的转换), 这里面有五个点:
- 操作系统调用 RustSBI 的方式是通过汇编指令
ecall对应的sbi_callid (实际叫 EID/EID), 这个过程在内核态下, 当然也有crate::sbi::封装好的以供使用 - 用户调用操作系统提供的系统调用是通过汇编指令
ecall对应的syscallid, 这个过程在用户态下, 会Trap 进内核进行处理, 内核解析syscallid并作出对应相应. - Trap可以理解为”用户程序在路上走着走着想要访问一些超出自己权限的东西,就像一脚踩空掉到陷阱 Trap 进内核了一样”, Trap的过程会保存上下文(寄存器等), 等从内核态回用户态时会恢复上下文. 仔细感受
Trap这个词, 是不是读音上就很有感觉? - 细分权限的意义在于: 你不能指望用户程序都是善意的,即使是善意的也不能假定其开发者是全知全能的,因此把敏感操作交给操作系统是安全考虑
- Rust 调用汇编指令是通过
core::arch::asm!或global_asm!, 我们上面已经见到了.
注意这个 arch 是 architecture 而不是 Arch Linux (?)
目前我们先试试不封装系统调用, 单独调用 sbi_call用于退出:
1 | fn sbi_call(which: usize, arg0: usize, arg1: usize, arg2: usize) -> usize { |
! 返回值表示函数是发散函数 永不返回.
要为你的用户做些什么
我们实现两个系统调用 sys_write 和sys_exit
1 | fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize; |
sys_write 系统调用会封装 RustSBIcrate::sbi::console_putchar, 当然还利用了 Rust 的宏和fmt 等使其更易用.
我们还需要给用户一个通用的 syscall 来实现系统调用:
1 | /// write syscall |
sys_write/sys_exit 将会封装为write/exit, 就像标准库一样提供给用户程序.
跑点什么?
我们之前说了实际上操作系统加载程序的最核心部分就是把应用程序可执行文件加载到内存.由于我们想一切从简(没错, 当你阅读到这时还远远不能称作入门),所以我们先只是把应用程序静态地放到内存的特定位置:这种情况下算是把应用程序作为内核的一部分了——有没有感觉什么不对?之前不是说应用程序在用户态吗? 这就暴露了另一个问题:我们只是实现了系统调用, 但 Trap 的过程没有任何控制!
我们将首先说如何把应用程序放入内存, 再介绍 Trap 过程
把应用程序静态地放入内存:
1 | core::arch::global_asm!(include_str!("link_app.S")); |
link_app.S 和 entry.S 类似,就是把应用程序的起始和终止位置标注, 设置内存布局并通过.incbin 引入二进制文件,还要开个数组记录一下各个程序的位置暴露给我们的操作系统使用(与汇编交互的过程可以自行搜索,大概就是 extern "C" { fn symbol(); } 这样):
1 | .align 3 |
操作系统中则是:
1 | extern "C" { |
即:
- 获取
_num_app的位置, 并通过转换为指针读到那个位置的num_app(应用程序数量),app_start(各个程序的起始位置),core::slice::from_raw_parts从裸指针的一块地址获取切片, 还有from_raw_parts_mut获取可变切片的 - 调用
fence.i清理i-cache(详见: - 把对应应用程序起始地址和终止地址之间的内存切片复制到
APP_BASE_ADDRESS的位置
这里我们不讨论具体的程序结构设计, 如何令程序模块化更好等.具体代码可以参考 rCore 的实现.
实现上下文切换
上下文切换的流程:
应用程序调用系统调用 -> 硬件触发Trap ->指令集设置寄存器(对RISC-V就是 stvec, scause等) -> 进入内核态并跳转到 stvec 所在位置 ->这个位置上的代码承担保存上下文和具体处理系统调用的职责 ->恢复上下文
我们逐个击破。
CSRs
RISC-V 中和 Trap 流程相关的寄存器是 CSR (Control andStatus Register)
| CSR 名 | 该 CSR 与 Trap 相关的功能 |
|---|---|
sstatus | SPP 等字段给出 Trap 发生之前 CPU处在哪个特权级(S/U)等信息 |
sepc | 当 Trap 是一个异常的时候,记录 Trap发生之前执行的最后一条指令的地址 |
scause | 描述 Trap 的原因 |
stval | 给出 Trap 附加信息 |
stvec | 控制 Trap 处理代码的入口地址 |
我们只需要通过stvec::write(__alltraps as usize, TrapMode::Direct), 把stvec 写入为我们 __alltraps 过程的地址
__alltraps 的实现
我们要保存寄存器, 但是问题是: 保存到哪?
C 应用程序在调用函数过程中也有保存上下文的概念,一般是把上下文中的调用者保存寄存器保存到栈上.但我们这里每个应用程序的栈空间暂时是重合的, 我们需要保存到别的位置,这也就需要我们引入”内核栈”的概念. 在比较完善的操作系统中,会在内核地址空间的高位存放不同应用程序的内核栈并且通过保护页隔开,这里对内核栈的理解应更偏向其特性和用途: 特性是由内核态代码访问修改,不受应用程序切换或者 Trap 影响, 用途是存放一些有以上特性的数据.
__alltraps 实际上要做的就是: 开局切换栈指针到内核栈,把通用寄存器保存到内核栈上, 把 CSR 寄存器保存到内核栈上, 构造TrapContext 上下文放入 a0 (相当于 x86_64 的%rdi), 调用trap_handler(注意等我们实现虚拟内存后就不能直接 call 了),trap_handler 用于实际处理系统调用(以及其它类型的 Trap):
1 |
|
__restore 的实现
别忘了还得从内核态回来. 我们用 __restore 做到这一点.首先要把 __restore 放在 call trap_handler的下一条地址位置, 这样从 trap_handler 返回后顺序执行到__restore . __restore 做的事情:
- 把内核栈保存的通用寄存器和 CSR 都恢复到寄存器中
- 切换到用户栈
- 调用
sret返回用户栈
这样, 我们就实现了所谓的”批处理操作系统”!
多道程序和分时多任务
如果我们有 5000 个应用程序, 每次执行某个程序都要加载一次消耗是巨大的.所以我们需要预先加载多个程序进入内存, 由内核调度决定运行哪个程序
如果有一个程序需要文件 I/O 操作占用大量时钟周期等待, 消耗也是巨大的.所以我们要实现时钟中断, 一个任务执行一段时间后保存状态并切换到别的任务,一段时间后再回来.
管理多道程序
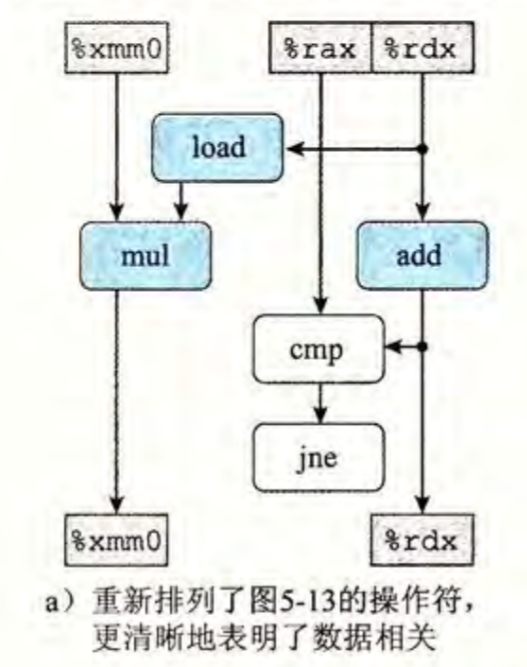
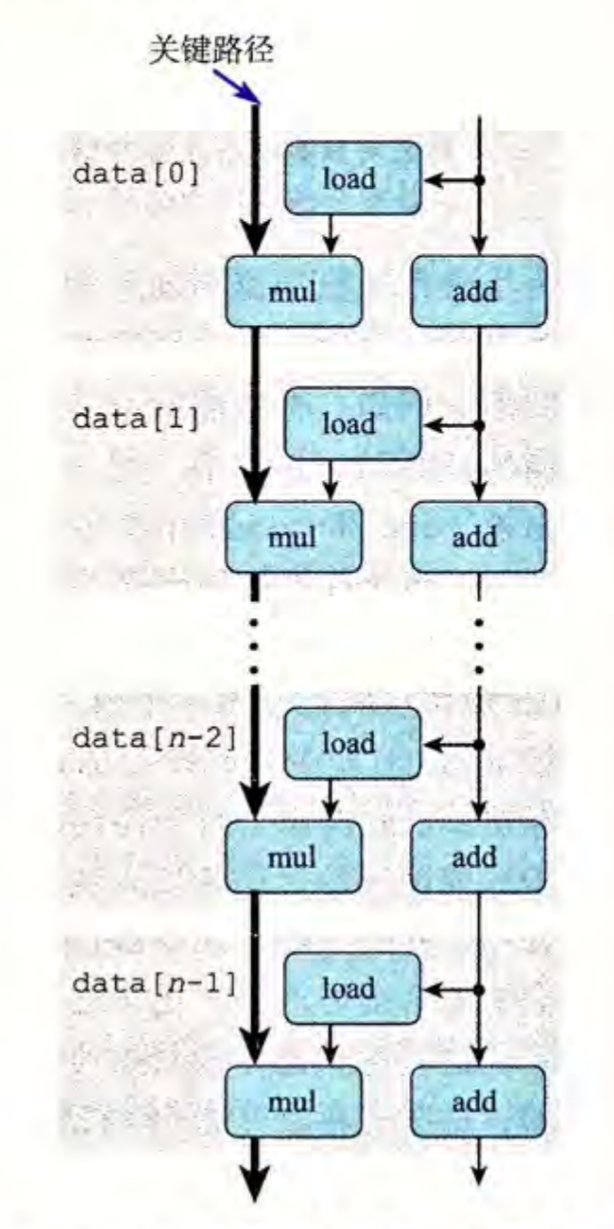
对于多道程序的放置, 实际上只需要把写死的APP_BASE_ADDRESS 改写为APP_BASE_ADDRESS + app_id * APP_SIZE_LIMIT 并相应修改load_apps 即可. 但是切换任务就比较麻烦,从一个任务切换到另一个任务的控制流是这样的:
A 任务 -> A的时钟中断Trap控制流 -> __switch ->B的Trap控制流 (-> 其他控制流) -> __switch返回 ->从其他控制流回到A任务
1 | __switch( |
switch 的职责是将内核栈保存到 current_task_context,并将下一个任务的上下文从 next_task_context中加载到当前寄存器
当然多道程序暂时还没有时钟中断Trap (分时多任务才有),所以切换任务的方式就是从任务主动调用 yield系统调用申请主动暂停并切换到下一个任务.
yield 系统调用的实现单纯就是把当前任务标记为停滞然后 runnext, run next 就是在当前维护的任务集合中找到下一个状态为Ready 的然后直接 __switch.
操作系统启动加载第一个用户程序(第一次进入用户态)就是构造一个空的上下文__switch 到第一个任务的上下文即可.
分时多任务
通过 riscv::register::time::read() 读取mtime 寄存器的值获取时间, 设置计时器.
计时器会触发一个 SupervisorTimer 的 Trap(Trap::Interrupt(Interrupt::SupervisorTimer)),我们可以在这个 Trap 的 handler 中实现抢占式调度:设置下一个计时器, 暂停当前任务并且切换到下一个可用任务.
1 | match scause.cause() { |
当然我们还要 trap::enable_timer_interrupt(), 用来设置sie.stie 以允许 S 模式下的时钟中断.别忘了操作系统启动后立刻设置计时器.
还记得我们说过 RISC-V 的一些术语和 CSAPP 规定的有歧义吗?
CSAPP 认为:
- 所有控制流的不连续处都是异常, 异常包括:中断, Trap, 故障, 终止, 以及 Linux 下的信号机制
- 中断: 外设异步触发的”通知”, 比如 DMA 访存完成后通知 CPU 触发中断,这里的外设是相对 CPU 而言
- Trap: 内核态和用户态转换的过程
- 故障: 例如虚拟内存缺页故障
RISC-V 语境下:
- 一些事件例如时钟中断既是中断也触发 Trap, 其实这也是符合 CSAPP视角的: 计时器也可以算作 CPU 的外设
- Trap::Exception 更接近故障或终止的概念, 在 RISC-V 语境下故障,终止都会触发 Trap
chapter3 练习跟白给的一样。
地址空间的实现
实现地址空间流程的简介
大概要介绍这些东西: 地址空间, 虚拟内存, 页表, 多级页表, MMU TLB 简介,虚拟地址到物理地址的翻译(查找页表从虚拟页号翻译到物理页号的过程), SV39分页模式
对于地址空间和虚拟内存的解释可以阅读 CSAPP 第九章的内容,也可以看我的导读博客, 这里简单做一下介绍:
为什么要有地址空间?
为了遵循”虚拟化”的原则,我们希望原则上每个应用程序可见的地址空间都是抽象为一个大的字节数组,每个元素对应唯一的一个地址, 形成每个应用程序独占一个地址空间的假象:多个应用程序如果共享同一个内存地址空间,会导致逻辑的复杂性(应用程序必须得知自己对应的内存区域)以及不安全性(应用程序可以访问甚至覆盖其他应用甚至内核的地址空间).所以必须包装一种抽象, 将物理主存的物理地址映射为虚拟地址.
通过以上叙述可知,我们需要为每个应用程序(以及内核本身)提供一个地址空间,以及将地址空间上的虚拟地址映射到实际的物理地址(毕竟事实上还是在 DRAM上存储的).
CPU如何通过虚拟地址访问物理地址的?
在得知了地址空间的必要性之后,我们开始理解虚拟内存实现不同地址空间的地址隔离流程.
内核维护一个称为页表的数据结构来维护虚拟地址到物理地址的映射,应用访问一个自己地址空间内的虚拟地址(VA), 而此时一个称为Memory Management Unit (MMU)的硬件通过查找页表获取到物理地址(具体细节下面会说).不过页表本质是存储在内存上的, 如果 MMU每次处理访存的翻译请求都要访问一次内存开销太大了, 于是单独设计了一个Translation Lookaside Buffer (TLB) 的缓存, 每次先从缓存中查找,如果没有再从内存中查找, 最后还找不到就触发缺页异常(Page Fault),由操作系统内核新分配物理页帧并且在页表中建立映射.
以上叙述大概说明了一个虚拟地址到主存上的物理地址的流程:虚拟地址访存请求 -> MMU -> TLB -> 主存上的页表 (->操作系统处理缺页 ->) -> 物理地址. 但是有很多新的名词: 什么是页?什么是页表? 什么是”缺页异常”与”物理页帧”?
分页机制
类似存储设备或缓存器中”块”的概念,我们将”页”(page)作为组织内存的基本单位,虚拟内存分割为虚拟页(VP),物理内存分割为物理页(PP, ’也叫页帧, Page Frame). 直观来说,Linux 的页为 4 KiB, rCore 的实现也是如此.
页的概念主要是为了更好地组织管理内存空间(你总不能以一个地址对应的一字节为基本单元吧,粒度太小了)以及处理虚拟内存大于物理内存的情况. 这是如何实现的呢?任意时刻虚拟页面都唯一处于”未分配的”, “已分配未被缓存的”,“已分配已被缓存的”三种状态之一,这里的”分配”指的是内核知道这段虚拟页面是已分配可访问的,但还没有被真正开辟物理页帧并记录映射,“缓存”是指开辟了实际的物理帧并且建立了页表上的映射:
如果读过 CSAPP 第六章的读者可以发现,虚拟内存机制实际上是把物理内存作为了虚拟内存的高速缓存,因此作为缓存的物理内存是可以比虚拟内存小的,毕竟有些页面是未分配/未被缓存的, 页也会
dealloc(如果真全满了 Linux 会调用 OOM Killer). 顺便说一下, DRAM缓存是全相联的.
有了数据本身(页), 我们还需要设计数据结构来管理这些页, 于是便有了页表.页表是若干页表项组成的列表, 每个页表项包含一些 flag (有效吗?可读可写吗?) 以及 n 位地址: 如果页表项有效,这个地址是一个虚拟页号(VPN),否则是一个物理页号(PPN).
如果是前者的情况, MMU 在查页表时读到无效表项时便触发缺页异常了. 当然,比较现代的设计一般会设计多级页表提高索引效率以及压缩页表实际使用大小:页表项指向另一个页表项, 再向下查找. rCore 实现则是三级页表.
对于一个给定的虚拟地址, 我们将其分为 VPN 和PO (Page Offset, 页偏移) 两部分. MMU从架构相关的页表基址寄存器 PTBR (对 RISC-V 来说是satp)中获取根页表地址, 通过虚拟页编号在页表中索引到物理页号 ppn,然后将物理页号和页偏移单纯地拼到一起组成最终映射到的物理地址.
如何从页表中通过虚拟页编号索引到物理页编号? 在三级页表的实现中,一个虚拟页号会有三部分作为三级索引,在创建虚拟地址到物理地址的映射(具体表现为记录到页表数据结构中)时内核会依次通过这三级索引找到对应节点的PTE (Page Table Entry) 所在的物理页帧 (SV39 分页模式中一个节点占一个页,如果在某一级索引中节点不存在就新开辟), 然后将 ppn 和 flags写入这个位置.
由上面的叙述可知,一个虚拟地址到一个物理地址的翻译是由虚拟地址页号页表中页表项记录的 ppn决定的, 没有规则上的必然映射关系.
至于 TLB 的缓存方式和一般高速缓存没有什么区别, 就是单纯分为 Tag IndexOffset, 映射到某组的某个缓存行然后找到对应偏移量, 详见
CSAPP 中给出了 Core i7 上的地址空间实例以及其页表项组织,下面我们看一下如何在 rCore 中结合硬件实现虚拟内存功能.
rCore 虚拟内存地址空间的实现
数据类型封装定义
我们需要将 usize 封装为具体的 VA / PA,并且实现基本的取整(对齐)功能和类型转换.
1 | impl PhysAddr { |
S 特权级的内存相关 CSR:satp
区分不同地址空间的页表基地址寄存器是 RISCV 的 CSR satp,其约定如下

MODE 设置为 8 即 ASID是一个 token 作为地址空间的标识符, PPN为页表的根地址(物理页号)
SV39 分页模式的对页表项的约定是:

可以看到 D A G 等就是 flags,具体意义可以查手册, 这里不再赘述.
我们的 PageTableEntry 实际上就是管理一个usize 的数据结构, 通过 bitflags crate实现标志位的读写, 并且设计读取 ppn 的接口
1 |
|
物理页帧分配
分配物理内存上的物理页面并管理, 通过core::slice::from_raw_parts_mut 引用物理页帧上的地址
这里采用了较为简单的后入先出式的物理页帧分配器,实际上就是记录管理一下物理地址, 毕竟对于内核来说
1 | pub struct StackFrameAllocator { |
设计 PageTable页表数据结构
作为管理一个页表(这个页表要放入 satp,作为一个独立的地址空间)的数据结构, 理应存储 root_ppn并且把子页表关系存入 frame. 这个数据结构中的frame 用来存”用于映射地址的那些页表项所在的 frame”,而实际作为内存存储数据的那些 frame 下面会提及
1 | impl PageTable { |
对虚拟页号的 3 个 indexes (SV39) 逐级查询多级页表(没有就创建)获取到虚拟页号对应的页表条目, 然后通过 map 与unmap, 把某个物理页号映射到某个虚拟页号, 逐级创建页表,并在最终页表条目存储 ppn
1 | fn find_pte_create(&mut self, vpn: VirtPageNum) -> Option<&mut PageTableEntry> { |
内核和每个应用都有自己的地址空间, 作为一个 Memory Set 数据结构.一个 Memory Set 包含一个当下地址空间的多级页表和多个逻辑段,逻辑段用于在比页更一级的抽象上管理内存, 通过
MapArea管理,这也就是内存中实际存储内容的 frame (而不是存储页表的)1
2
3
4pub struct MemorySet {
page_table: PageTable, // 存储页表的 frame
areas: Vec<MapArea>, // 数据页的 frame
}每个 Memory Set 中的页表由
satp中记录的 token 区分(SV39)Memory Set 需要实现:
- 映射一段虚拟地址到逻辑段中的物理帧
- 取消映射: 对齐, 分配物理帧并纳入管理(insert), 页表把这个 (虚拟页号,物理页号) 键值对映射进去
内核地址空间和应用地址空间的逻辑段分布, 直接根据这个分布 map逻辑段就行
应用地址空间还要调整一下链接脚本(因为有了地址空间可以共用一个链接脚本了),借助
xmas_elf解析 ELF 文件然后 Memory Set 依据文件的section 映射到逻辑段TODO这里还要说一下内核地址空间和应用地址空间的内存排布,以及跳板的作用(内核地址空间和应用地址空间中跳板页的地址相同,可以”跳转”过去).TODO切换/加载/执行应用程序satptoken 详细说明: 硬件, OS, 操作系统职责的边界- Trap 的修改:
- 不再只是单纯交换
sp和sscratch切换内核栈和用户栈,原本切换后指向用户栈的应该指向应用地址空间内的上下文位置 sfence.vma刷新 TLB
- 不再只是单纯交换
- 改进 Trap 处理这一块比较复杂, 到时候慢慢说, 尤其是跳板这一块
chapter 4 实验 lab2:
sys_get_time和sys_trace之所以失效, 是ts指针的地址是虚拟地址, cpu 访存时通过 mmu 翻译, mmu去查询页表,但是很可能这个时候这个用户态的虚拟地址还没有被映射到实际物理页面.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22let token = current_user_token();
let mut buffer =
translated_byte_buffer(token, ts as *const u8, core::mem::size_of::<TimeVal>());
if buffer.len() == 1 {
let slice = &mut buffer[0];
let ts_ptr = slice.as_mut_ptr() as *mut TimeVal;
unsafe {
*ts_ptr = tv;
}
} else if buffer.len() == 2 {
unsafe {
let tv_bytes = core::slice::from_raw_parts(
&tv as *const _ as *const u8,
core::mem::size_of::<TimeVal>(),
);
let first = &mut buffer[0];
let first_len = first.len();
first.copy_from_slice(&tv_bytes[..first_len]);
let second = &mut buffer[1];
second.copy_from_slice(&tv_bytes[first_len..]);
}
}至于
mmap和munmap,对一个虚拟地址区间内的所有地址进行 translate (其中有find_create_pte), 构造相应的权限MapPermission, 然后插入对应MemorySet的MapArea.
进程管理的实现
学过 15213 的人会对进程这一块有一定的理解, shell lab 这一块.这一章内容也比较简单.
目前来讲的 Task 已经很接近一个进程的概念了:每个进程一个独有的地址空间, 具备各种状态且能够被内核调度,只是我们还需要维护 pid 以及实现进程相关的 forkexec waitpid 系统调用.
每个进程的标识
控制块中加入 PidHandle 记录 pid,以及要实现根据应用名链接程序并且加载到地址空间的功能
设计修改:
- 把涉及到进程调度 处理控制流的部分分离出来到
Processor中- 默认进行一个
idle进程作为待机时运行的进程 - 调度 (如
run_task或schedule)时会构造上下文并__switch到别的进程 - 进程主动
yield会__switch到idle进程
- 默认进行一个
- 进程控制块包含了
PidHandle, 内核栈, 上下文, 进程状态,进程地址空间等 TaskManager需要包含一个等待队列ready_queue. 这里的调度算法是简单的 RR 算法(练习里是改为 Stride 算法),即单纯地先进先出:add添加任务到队尾,fetch从队首拿出任务.
进程相关操作
记得创建初始进程
initproc(只是单纯加载initproc应用并且add_task)fork需要复制父类的地址空间, 维护父子关系,同时注意一下父进程和新生成的子进程返回值不同首先复制
MapArea记录的逻辑段.注意子进程需要获得和父进程相同的逻辑段布局/映射方式和权限控制,不过在实现上我们并不会在复制MapArea时复制父进程数据页的物理页帧,因为虽然我们的虚拟地址空间在抽象层面上是隔离的,物理帧却是实实在在不能共享的, 而是应该具体地新分配页帧然后复制过去(换句话说 父进程的data_frame是拥有所有权的,并且不应当被子进程引用更不应当被移动, 而是应该新分配 frame后复制数据)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15impl MapArea {
pub fn from_another(another: &MapArea) -> Self {
Self {
vpn_range: VPNRange::new(
another.vpn_range.get_start(),
another.vpn_range.get_end()
),
// 这里不能直接.clone(), 直接复制过来的是同一份物理页帧和物理地址
// 应当等到下面重新分配数据页物理页帧后复制
data_frames: BTreeMap::new(),
map_type: another.map_type,
map_perm: another.map_perm,
}
}
}然后对逻辑段进行遍历, 对其中每个段分配物理页帧,创建页表映射并且复制数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19impl MemorySet {
pub fn from_existed_user(user_space: &MemorySet) -> MemorySet {
let mut memory_set = Self::new_bare();
// map trampoline
memory_set.map_trampoline();
// copy data sections/trap_context/user_stack
for area in user_space.areas.iter() {
let new_area = MapArea::from_another(area);
memory_set.push(new_area, None);
// copy data from another space
for vpn in area.vpn_range {
let src_ppn = user_space.translate(vpn).unwrap().ppn();
let dst_ppn = memory_set.translate(vpn).unwrap().ppn();
dst_ppn.get_bytes_array().copy_from_slice(src_ppn.get_bytes_array());
}
}
memory_set
}
}当然, fork 还要创建进程上下文, 维护父子关系;最后将这些信息汇总到进程控制块中返回.
实际的系统调用
sys_fork则需要封装fork并且add_task.fork是个很神奇的函数, 调用一次返回两次. 而 rCore的实现中, 父进程收到的返回值就是函数返回值, 而子进程收到的返回值是sys_fork中对进程上下文设置的trap_cx.x[10] = 0;exec直接从elf_data覆盖地址空间,初始化 Trap 上下文. 由于覆盖了旧的地址空间,trap_handle中必须重新获取上下文.退出和等待回收的逻辑也比较直观.
子进程退出并不会立刻被内核清理, 而是变为
zombie状态,在父进程waitpid后才会被回收资源.
如果父进程比较不负责任提前退出, 这个子进程会挂在initproc下面成为初始进程的子进程并由initproc负责回收.
chapter 5 实验 lab3: 最简单的一集
修改 fetch 逻辑为遍历任务队列中 stride最小的任务并返回. 理应使用优先队列, 但此时我还在与 no_std搏斗并不知道 alloc crate 是有二叉堆的, 所以就懒了()
1 | pub fn fetch(&mut self) -> Option<Arc<TaskControlBlock>> { |
其中 stride 由每次调度到此任务时 + pass维护. 一个任务的 pass 计算方式为:
!!! 把这一章的
sys_spawn迁移到下一章 lab 时,注意创建进程控制块时对文件描述符要创建StdinStdoutStderr(不过我们这里Stderr就是简化为Stdout)坑了我挺久的。这个句号还是我打拼音特意打出来的, 足见我的怒火.
文件系统实现
基于 Filetrait 实现的文件描述符及其接口
活用 Rust trait, 一个文件应当具有 Read Write 行为, 即提供read write 以及是否可读可写的接口.
我们还需要在地址空间里防止缓冲区, 用于读取文件内容并放入其中.
文件系统的实现
一台计算机的存储层次大致可以分为:
- 最底层的 块设备驱动, 封装为
BlockDevice接口 - 直接用块 Cache 读写存储器上的块, 这是比较常见的做法
- 目录存储格式: 超级块/索引块/数据块, 用于管理和组织块存储数据的情况,下面依次介绍
- 块管理器和
Inode, 封装起来使其更易用 - 内核通过这些抽象层暴露的接口进行文件管理
块设备接口层封装
这里我们的操作系统目前是跑在 QEMU 上的, 而在 QEMU 上可以通过VirtIOBlock 访问 VirtIO 块设备.首先要添加一块块设备
1 | qemu-system-riscv64 \ |
其中 FS_IMG 是我们打包的 easy-fs文件系统磁盘镜像(后面会说), 这里命名为 x0.-device 一行则是将设备添加到 VirtIO 总线, 通过MMIO 进行控制 (在内存中一块特定的物理地址用来访问控制外设.磁盘也是外设.)
这里由于我们主要讨论操作系统而不是更底层的硬件设备驱动, 所以省略.感兴趣可以查看
块缓存(意义及其实现)
磁盘访问速度非常慢, 在实践意义上是必须要用缓存利用局部性减少浪费在I/O 上的开销的.利用缓存和一些常见的替换算法来间接访问较慢的设备是常见的方法.
这里我们一个块是 \(512\) 字节
Inode 概念: 记录文件元信息
存储设备以块为基本单位,但是我们的文件系统通产需要提供读写特定文件(包括目录也是文件)的功能.那么建立块到文件的映射(或者说管理一个文件都存储到哪些块上了)就是必要的.
为了表述方便,我们称记录文件实际数据和元信息的块为数据块,记录这些数据块存在哪的块叫记录块 (只是表述方便,并非专有名词.)
这里我们可以灵活地记录不同大小文件的块占用:
- 当文件很小时, 由
direct中INODE_DIRECT_COUNT个数据块来记录文件的i(\(\text{i} \leq\text{INODE_DIRECT_COUNT}\) ) 个数据块 - 当文件更大时, 多出来的部分由
indirect1指向的某个记录块来记录, 这个记录块的每个u32都指向一个存储文件信息的数据块. 这个记录块就是一个块的大小 - 当文件实在太大, 多余的部分只能再用
indirect2指向的一个记录块来记录, 这个记录块指向
1 |
|
DiskInode 还需要提供get_block_id获取其中记录的第 id 个(这里是相对于这个 inode自身而言的索引)数据块的块编号(这个就是实际块设备上的块编号).随后提供块的读写接口, 使用户免于调用更底层的更危险的接口.
我们还需要一个 DirEntry 来提供比较人话的索引方式,例如存在两个目录项 /test.txt 和 /foo.txt,可以理解为根目录的 inode 节点中记录保存有两个 DirEntry,name 分别为 test.txt 和 foo.txt.我们未来实现 linkat的时候就是要在根目录节点中拓展一部分空间然后把新的 DirEntry放进去, 这个新的目录项 name 为硬链接的路径名,inode_id 就是要被链接的已存在文件的inode_id.
!!! 注意, 我们在磁盘布局中很明显能看出, Inode 本身也是存在磁盘上的,我们从名字也能看出来:
DiskInode是从磁盘读出来,通过特定接口方法读/写回磁盘 (实际上是写到块缓存,等块缓存被替换时写回磁盘设备)这一点为我们添加
nlink字段记录硬链接数量信息奠定了基础.
Bitmap 概念: 记录哪些块使用了
虽然有了 Inode, 但是我们对块的管理还是远远不够的. 例如,我们现在只能知道一个文件的数据都被记录在哪些块上,但我们并不知道哪些块被分配了而哪些块是空闲的.文件大小的不同导致了整个文件系统的不规整性质,所以必须有一个数据结构记录并管理. 为了节约空间, 每个 u64管理记录 \(64\) 个块的空闲与否,并且提供找到一个空闲块分配返回其块编号.
1 | pub struct Bitmap { |
Bitmap 实现: 分配某个 bit
alloc 直接查找并返回第一个未被分配 (u64中第一个为 0 的位) 的块编号. 为叙述方便我们称这个被找到并分配返回的块为\(\text{B}\)
从 Bitmap 的内部编号到块编号是这样计算的:block_id * BLOCK_BITS + bits64_pos * 64 + inner_pos as usize
block_id * BLOCK_BITS用于得到bit64_pos表示u64中, 则他前面还有bit64_pos * 64个块inner_pos表示u64中的第几位, 他前面还有inner_pos个块.
SuperBlock: 管理I-Bitmap 和 D-Bitmap 本身
难绷的是还需记录 Inode Bitmap 和 Data Bitmap 本身占用了哪些块,于是就有了 SuperBlock
存储布局(目录存储格式):
SuperBlock | I-Bitmap D-Bitmap | Inode | Data |
|---|---|---|---|
| 记录 I/D-Bitmap 占用的块 | 记录 Inode 和实际文件数据占用的块 | 记录实际文件的数据和元信息在哪些块上, 并提供封装接口对其操作 | 实际文件数据. 极端一点地想, 其实只有这些是我们需要存的,其他都是为这些服务的 |
还需要做的事情
我们已经完成了文件系统的本质职责: 块管理器 (包含 block_device 设备,i-bitmap, d-bitmap, 以及具体 inode/data 开始的 block 位置).下面是操作这些模式:
- 创建根目录, 索引节点方法
- 文件处理相关接口 (列举/打开/清空)
- 内核索引管理
- 将应用打包为文件系统磁盘镜像, 修改
sys_exec中elf_data的来源 - 对接 qemu (主要是实现 block device 这一块, 即上面说的那些
VirtIO设备相关的)
chapter 6 实验 lab4: 写得比较折磨, 主要是第一次接触文件系统相关的
sys_fstat非常简单1
2
3
4
5
6
7let sts = Stat {
dev: 0,
ino: inode.inode_id(),
mode: inode.mode(),
nlink: inode.nlink(),
pad: [0; 7],
};如前面所说的,
nlink直接在DiskInode结构体中, 保存在磁盘 Inode 里.剩下就是把这个结构体放到参数传进来的指针指向的地址去, 和 lab1 的
sys_get_time差不多, 翻译一下虚拟地址得到物理地址的 mut引用, 然后考虑在两个页上的情况把数据复制进去.sys_linkat有些麻烦:经过一些无聊的 validate, 找到
old_name对应的inode_id, 然后在拓展根目录的 inode 节点空间, 新插一个名为new_name, 对应inode_id为刚刚找的inode_id的目录项, 维护一下这个 inode 的nlink.sys_unlinkat大同小异, 就是找到对应 id 的 inode然后填充为DirEntry::empty(), 如果nlink为\(0\), 还要 clear 掉这个inode.
管道实现
比较直观, 就是创建一个 pipe 数据结构对接两个文件描述符, 实现 read /write, 以及中继 buffer
然后在 shell 上实现以下重定向, 复制文件描述符
当然, 首先要对 shell 实现传参的能力, 解析参数入栈即可;这样之后才能解析到 > 和 < 的重定向
多线程实现
线程模型和相关概念的简介
- 线程(在我们实现后)是操作系统调度的任务单位
- 一个进程里的每个线程共享这个进程的地址空间,但是有自己的用户栈
- 进程之间没有父子关系, 但是有个 main thread,这个线程退出后进程也退出
核心数据结构
此时进程不再是调度的最小单位, 而是线程管理的容器,所以要记录其线程的引用.
我们要创建线程控制块记录线程的 tid, 独立用户栈,线程所属的进程的 Weak 引用, 以及其他必要信息.
相应机制的实现
- 新建线程需要维护与其所在进程的关系, 分配用户栈/内核栈和跳板页,放入调度队列中(现在调度队列调度的已经是线程而不是进程了),最后新建上下文.
- 退出线程即切换到下一个线程. 主线程退出后这一进程也会退出.
- 等待线程结束: 根据
tid找到线程列表中的任务,如果已经退出就清理 - 由于只是更改了调度的粒度, 其他操作没什么大的更改.
同步互斥
上面明确提及了一个进程里的每个线程共享这个进程的地址空间,这就导致了不同进程之间很可能出现数据竞争.
下面是一些术语:
- 临界区: 由于一些运算是多条汇编组合成的, 多线程下可能会有竞态条件,这个访问共享变量的代码片段就是临界区
- 原子性: 原子即不可分割的(不要谈物理XD),表示这一个代码片段要么全部不执行要么全部执行, 不会被打断
- 锁(互斥锁): 由上面两条, 很自然地产生一个想法: 要想保证代码不变成dilemma, 我们必须保证临界区的原子性.互斥锁就是来保证这一点的, 在临界区开头上锁, 结束时解锁,只有唯一持有锁的线程才有资格执行临界区的代码(不可重入性).当然在比较现代的高级语言,一般通过语法将互斥锁绑定到某个共享变量身上.
- 信号量: 当某些线程并发确认不会出现竞争,但我们希望不要由太多线程同时访问数据时,使用信号量控制一个数据同时被线程访问的最大容量
- 条件变量: 用于需要检查某一条件合适的时候再执行线程的情况. 主要是由
wait(condition?)和signal()实现.需要检查合适条件 (这里用谓词condition?表示) 的线程调用wait解锁资源让出时间片让其他线程被调度执行, 当某个可能使得condition?成立的线程被调度执行, 且令condition?为真后, 这个线程执行signal()通知刚才休眠的线程. 这个过程是基于一个等待队列wait_queue实现的 (不然没法判断通知哪个任务) - 死锁: A 等待 B 的资源, B 也等待 A 的资源, 互相等待导致永远无法结束.常见的情景是 B 上锁 \(m_1\),但是随后等待另一个锁 \(m_2\) (假设被 A持有), 而此时 A 也在等待 B 解锁
同步互斥的实现
Mutex
既然是要”锁”, 那就要有
lock和unlocklock的逻辑就是: 如果这个锁当前已经是锁住的状态,则阻塞自身等待并通知内核调度其他任务; 否则就设定为锁住的状态unlock将互斥锁设定为解锁状态,寻找等待队列中的任务并调度Semaphore
Dijkstra 说的道理:
1
2
3
4
5
6
7
8
9
10fn P(S) {
S = S - 1;
if S < 0 then
<block and enqueue the thread>;
}
fn V(S) {
S = S + 1;
if <some threads are blocked on the queue>
<unblock a thread>;
}我们维护的这个 \(S\)就是当前资源还有多少可访问的盈余, \(P\)操作就要减少可访问的资源数,如果资源数不够了就要阻塞当前线程并且调度其他线程等待其他线程让出资源;\(S\) 操作为让出资源,就要增加可用资源数,同时在等待队列中找到因为资源数不够而被阻塞等待的线程唤醒(放入任务调度队列)
Condition Variable
上面给的比较具体了, 就是一个
wait_queue, 等待线程调用wait进行锁资源的解锁(防止死锁)然后阻塞自身,等再次调度回来后再获取锁; 修改条件线程调用signal从wait_queue中获取一个需要通知的线程,通知内核调度唤醒这个任务.1
2
3
4
5
6
7
8
9
10
11
12
13
14pub fn signal(&self) {
let mut inner = self.inner.exclusive_access();
if let Some(task) = inner.wait_queue.pop_front() {
wakeup_task(task);
}
}
pub fn wait(&self, mutex:Arc<dyn Mutex>) {
mutex.unlock();
let mut inner = self.inner.exclusive_access();
inner.wait_queue.push_back(current_task().unwrap());
drop(inner);
block_current_and_run_next();
mutex.lock();
}
chapter 8 实验 lab5: 死锁检测
这个 lab 我自己写出的死锁比我代码 detect 出的死锁还多, 还有exclusive_access 嵌套调用导致的BorrowMutError, 也挺痛苦的 ()
process 里实现了一个detect,因为锁之类的资源是对所有线程可见的进程资源,所以available allocation need数组(实际上我分成六个数组区分 mutex 和 sem )应该在 PCB inner 里.
主体逻辑是在 detect 函数里,syscall 里就if deadlock_detect && !detect(...) 然后返回-0xDEAD
lock unlock up down 维护 availableallocation need 三个数组.
sem 实际上就是把 available 的初值从 mutex 的 1 改为 count,其它没什么变化.
]]>