一 核心内容
本论文提出了名为 Tigon,一种基于 CXL Pod 的分布式内存数据库。
论文作者注意到 CXL 标准在强缓存一致性实现上 Snoop Filter 记录的缓存行信息过大、现有 CXL 硬件实现通常仅仅支持一小部分内存的缓存一致性,充分利用这一点划分了 HWcc 和 SWcc 区域,通过在 SWcc 中存储松散一致性的实际数据、在 HWcc 中存储高频同步原语的方式,高效地在 CXL Pod 架构下管理了跨机活跃元组(Cross-host Active Tuple, CAT)在不同主机间的迁移,利用 CLOCK 算法管理有限的 HWcc 空间,驱逐非热点数据。
在数据库本身的特性方面,Tigon 采用 2PL 两阶段锁(元数据保存在 HWcc)策略,结合 CXL 共享内存的特点改进了 Next-Key Locking 协议解决幻读问题,利用 CXL 共享内存的特性避免了 2PC 两阶段提交。
二 研究背景
关于 CXL 可以看 computeexpresslink.org 或 这篇论文笔记 的背景介绍.
在本篇论文的语境下,将通过 CXL 总线共享 CXL 内存的机器集群称为 CXL Pod.
传统的分布式数据库通过网络或者 RDMA 支持超远距离的分布式计算节点之间的通信,但基于 TCP/IP 的通信会产生较大的协议栈和上下文切换开销,RDMA 也依然具有较大的延迟。基于 CXL 链路的分布式节点虽然没有基于网络的分布式节点那么远的通信物理距离,但是 CXL 相对前两者来说延迟更低、吞吐量更高。然而,CXL 链路和 DRAM 的引脚相比依然延迟更高、带宽更低。DRAM 的顺序访问带宽可以达到 250GB/s 左右,而 CXL 只有 50GB/s 左右。CXL 标准的缓存一致性代价也较高,Snoop Filter 需要为每个缓存行维护元信息,导致当前许多硬件只实现了一小部分内存的缓存一致。
另外,在分布式数据库中,尽管数据库本身的规模可能很大,但是在不同主机上运行的事务并发读写的数据元组集合规模可能很小:每个事务只包含较小数量的元组,而并发运行的事务一般与核心数相当。以论文中的介绍的 TPC-C 测试为例,单个事务平均访问 39 个元组,总数据量约 7KB。假设系统配备 1000 个核心且每个核心执行一个事务,则系统至多存在 3.9 万个活跃元组,对应约 7MB 数据。我们将此类元组集合称为”跨主机活跃元组”(简称 CAT)。这启发了使用 CXL 共享内存只迁移和共享这些 CAT 的方法。
三 Tigon 系统设计
分区与共享内存
Tigon 采用 Pasha 架构。Pasha 架构将计算与存储解耦,由 CPU 计算节点和 CXL 共享内存内存存储节点构成,将数据库索引(B+Tree等)存储在 CXL 共享内存中。
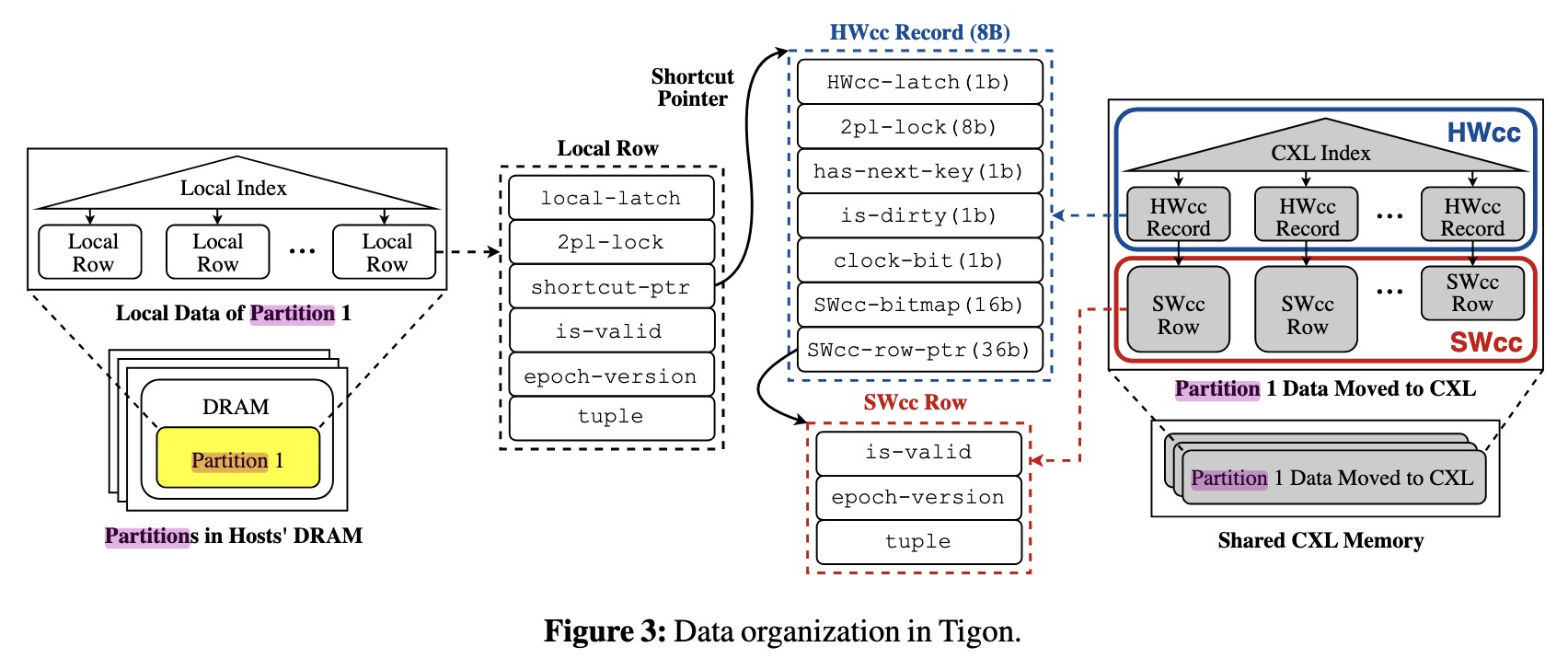
整体数据库中的数据先在不同的 CXL Pod 节点中分区,初始阶段每个主机是其分区数据的所有者(Owner),数据最初在主机的 Local DRAM 中,此时访问具有低延迟和高带宽。
当节点需要操作远端节点中的数据时,该数据就由那个节点的 Local DRAM 转移到 CXL 共享内存中,成为 CAT 的一部分。后续的跨主机同步操作都可以靠对 CXL 内存的原子操作实现,而无需昂贵的网络消息开销。当然,如果某个节点想要在远端节点的数据分区中插入数据,还是需要网络消息通知那个远端节点,但仅仅只是一个插入通知:远端节点将一个占位元组插入并转移到 CXL 共享内存,由当前节点通过原子操作修改这个占位元组中的数据。
当某个节点想访问的 CAT 已经被其他节点获取了 latch 时, 这个节点必须自旋等待. 但是在 Tigon 的设计中, 自旋等待无需每次都通过 CXL 链路访问 CXL 中的 HWcc latch 导致昂贵的开销. 第一次自旋访问 HWcc latch 时会 cache miss 并加载到 CPU 高速缓存中, 则之后的每次自旋都是 cache hit, 称为本地自旋. 当持有锁的节点释放锁后, CXL HWcc latch 状态改变, 由于 latch 在 HWcc 区域, Snoop Filter 会根据 CXL 3.0 的缓存一致性协议更新自旋节点的 CPU 缓存, 自旋结束, 此节点获取到锁.
传统的分布式数据库实现需要基于网络通信的两阶段提交,而 Tigon 只需要基于 CXL 链路的 CXL 原子操作即可。由于涉及跨主机访问的元组都在 CXL 内存中,单机就可以锁定所有资源、决定事务的提交与终止、写入日志等,极大便利了数据库实现,避免了 2PC 的开销。
数据结构设计
CXL 共享内存中
Tigon 将高频同步元数据放在 HWcc 内存区域中,包括索引(CXL Index)和
HWcc Record; 将实际元组数据以 SWcc Row 的形式放在 SWcc
内存区域,包含用于判断是否已经成为墓碑(见下文)的 is-valid
标记、用于判断何时能将墓碑空间释放的
epoch-version、以及元组数据本身 tuple。
HWcc Record 的主要字段以及用途如下:
HWcc-latch: 数据库中对元组数据的 latch \(^{[1]}\), 防止多主机或多线程同时访问造成不一致性2pl-lock: 用于记录两阶段锁状态has-next-key: Next-Key Locking 的改进。由于 Next-Key Locking 需要锁住 next key 来避免幻读问题,而 CXL 共享内存可能并未加载这个 next key,所以通过这个标志位记录当前 CXL Index 的下一个 key 是不是在 Owner 那里时真实的下一个 key(因为 CXL 只加载 CAT,很可能当前 key 在 CXL Index 里的下一个 key 是其他的 CAT)。这个维护由 Owner 在获取 CXL Index B+ Tree 锁后修改索引时顺手维护,在 Next-Key Locking 时需要检查。若has-next-key为真则无需额外操作,否则需要从节点的 Local DRAM 里再加载到 CXL 内存中。is-dirty: 用于记录 CXL 内存中的数据是否被修改过(是否和 Owner Local DRAM 里的数据相同),如果未被修改则 Owner 访问时可以不读 SWcc 中的数据而是在 Local DRAM 中访问,节省 CXL 带宽。clock-bit: Tigon 采用 CLOCK 算法而不是 LRU 算法来管理 HWcc 中数据的进出。SWcc-bitmap: 缓存有效性位图,若当前主机对应的位是1则说明本地 CPU 缓存有效,否则则需要 flush,强制从 CXL 读取最新数据并重设位 1。当有主机需要更新 SWcc Row 时会清零所有缓存有效位,通知它们主机的本地缓存已经无效了。SWcc-row-ptr: 指向在 SWcc 中的 SWcc Row,这部分记录实际数据。
\([1]\) : 数据库的语境中将管理较高逻辑层次的事务的同步原语称作锁(lock),将保护数据库系统实现中本身对象的同步原语称为闩锁(latch)。区别主要在于,latch 更接近 OS 语境下的锁,需要实现者手动控制、手动防止死锁;而 lock 由事务管理器控制,有死锁也会有单独的方案自动恢复。
Local DRAM 中
Local DRAM 中由 Local Index 索引的 Local Row 同一般数据库中的元组及其元信息一致,如两阶段锁标记、epoch 版本、实际元组数据。
但除此之外还包含了一个 shortcut-ptr 指向 HWcc Record. 当
Local DRAM 中的元组成为 CAT 并移动到 CXL 后,CXL
共享内存中的这个元组才是真实最新的数据,本地只是一个即将被替换的副本,所以理论上即使是
Owner 自己要访问时也必须要查 CXL Index 然后访问 CXL 中的数据,但这对于
Owner 来说还要查一下 CXL Index 实在没有必要,因此 Tigon
在这里做了一个小优化,通过 shortcut-ptr 直接记录本地元组在
CXL 内存中的位置(HWcc Record),无需再查询 CXL Index.
并发与事务一致性管理
防止 Use After Free
is-valid
is-valid 为 false
的通常作为墓碑或占位符,其数据无意义,但能代表某些语义
占位符:当某个主机想在远端主机所拥有的分区插入数据时,需要让远端主机先插入一个
is-valid = false 的占位符并加载到
CXL,然后当前主机再抢锁并修改数据。
墓碑:CXL 中的某个元组被 CLOCK 算法判定应写回主机
Local DRAM 后,这个元组在 CXL Index
中被删除,但此时还不能直接释放空间,由于这里的设计必须是先获取 HWcc
Record 的裸指针再通过原子操作 HWcc-latch
获取锁,所以即便写回数据需要获取锁,也可能有一些主机提前拿到了裸指针,这里只是将其设置为
is-valid = false 的墓碑,避免其他主机拿到裸指针后 CAT
被写回原主机导致解引用时 Use After Free.
当确认没有任何主机引用这个对象时,这个对象才能被安全释放空间。而判断是否还有主机引用这个对象则需要
EBR.
版本标记 epoch-version
和传统数据库中的版本管理类似,epoch 类似一个主机的 timestamp (约 10ms
更新一次,作为一个 epoch), 标志当前主机在运行哪个 epoch
的代码。读操作只能读被标记为 epoch <= current_epoch
的元组,垃圾回收可以回收 epoch <= current_epoch
的旧版本快照。
上文说到判断是否有主机引用等待释放的对象需要 EBR (Epoch-Based Reclamation), 如果某个墓碑的 epoch-version 在所有主机的 epoch 之前,即它是在所有主机当前运行的版本之前被删除的,那么可以放心释放空间。换言之,即使存在一个主机运行在比墓碑更早的 epoch 上,那这个元组也并不会被释放。
日志与恢复
Tigon 的日志采用并行记录、并行重放的机制. 每个 worker 都写入自己的日志到 log buffer, 根据 epoch (10ms) 进行组提交 (写入SSD). 只有一个 epoch (及其之前的 epoch) 的全部日志都被提交落盘后, 这个 epoch 才算被成功提交.
四 性能评估
使用 Intel 虚拟化技术模拟 CXL 硬件.
- 对比 Shared-nothing 架构 (数据分片, 各节点不共享数据) 的数据库吞吐量提升了 2.5 倍
- 对比 RDMA 数据库吞吐量提升了 18.5 倍
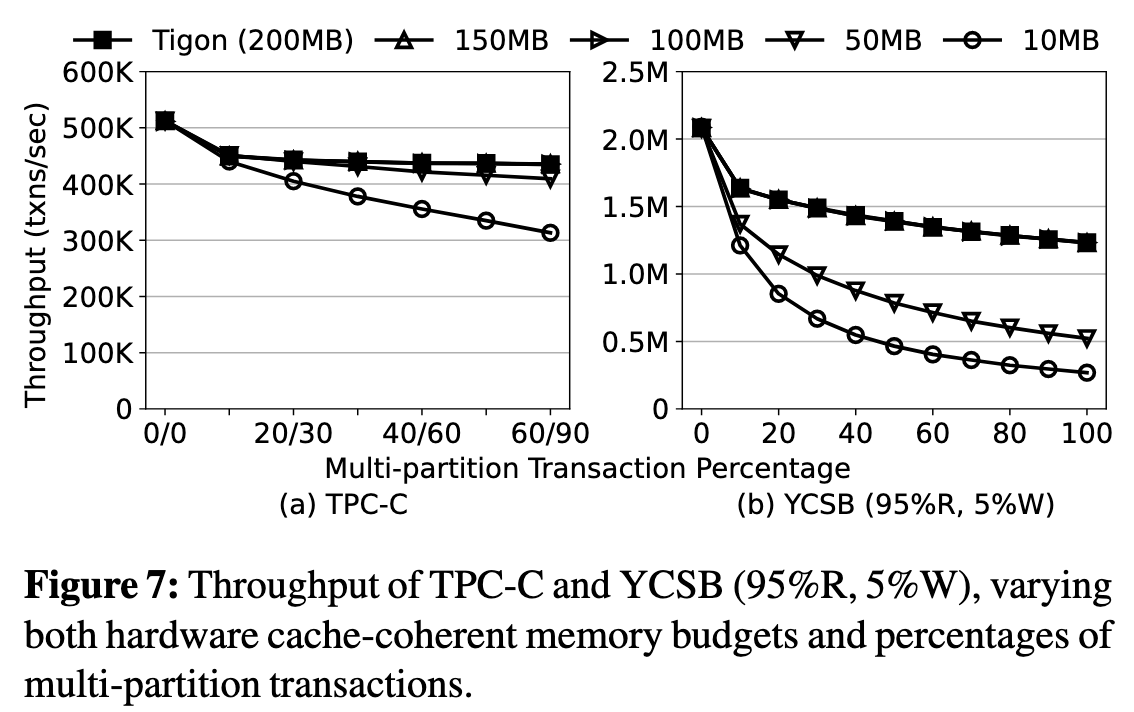
HWcc 空间大小:
当硬件的缓存一致预算不足时, 哪怕只有 50MB, Tigon 的性能下降也只有 5.8%, 可见 CLOCK 算法能精准识别热点 CAT 以管理 HWcc 空间的驱逐. 当 HWcc 空间只有 10 MB 时, 出现比较严重的缓存抖动, 吞吐量下降较大
五 阅读总结
主要思路是一反其他研究方向将 CXL 透明化的思路 (但其实之前 CtXnL 对用户态也不是透明的, 毕竟还是有 CTLib allocator), 将 CXL 内存视为不透明的通信介质 “中转站”, 或者说是一个共享缓存. 总之充分利用了数据库的负载特性 (CAT 较小等) 设计了符合 CXL Pod 架构特性的数据库系统.