本文中的 NVM (Non-Volatile Memory) 和 上一篇 NOVA 中的 NVMM (Non-Volatile Main Memory) 是相同的概念。
一 核心内容
论文作者提出了一种名为 Strata 的多层次文件系统,同时管理 NVM/SSD/HDD 等多种存储系统结构层次。Strata 为用户态、内核态、存储层次进行了职责划分,进一步为 NVM/SSD/HDD 的多层存储系统上的应用程序降低延迟、提高吞吐量。
Strata 主要分为用户态的 LibFS 和内核态的 KernelFS。LibFS 负责记录 per-process 的 Update log 以及进行热点数据缓存,KernelFS 主要负责 Digest 操作。NVM 中的 Update log 能够保证写入的同步语义;Digesting 通过日志合并将随机写转化为顺序写,契合 SSD 的硬件特性。
为了保证 LibFS 的 Kernel Bypass 不会导致并发安全问题且避免大量轻度写操作的大量锁开销,Strata 采用租约(Lease)操作防止两个线程绕过内核同时修改同一个文件。
Strata 还提供了对程序员更友好的同步写入、顺序可持久化语义,并且通过合并 log 改善了传统 LFS 的写放大。
二 研究背景
大部分传统文件系统只针对特定存储设备,面对复杂的存储设备层次结构时不能充分利用其硬件特性降低开销。另外,现代应用的性能瓶颈逐步由计算转移到 I/O 上,因此对现代应用(如键值存储、数据库)对性能和功能的需求远超传统文件系统的舒适区:
- 一些程序的业务场景需要大量的小型分散式更新,反复进内核
copy_from_user拷贝数据开销太大,需要常态内核旁路来实现盲写的零拷贝 - RPC Server 必须在响应前持久化数据,异步的
write()会在写入 DRAM 页缓存后就返回,需要手动调用fsync(),对编程不友好。开发者倾向于有符合直觉的同步顺序写入语义 - 部分文件系统牺牲强一致性保证性能,或为了保证性能牺牲了强一致性。应用程序需要高效可靠的崩溃一致性
三 Strata 系统设计
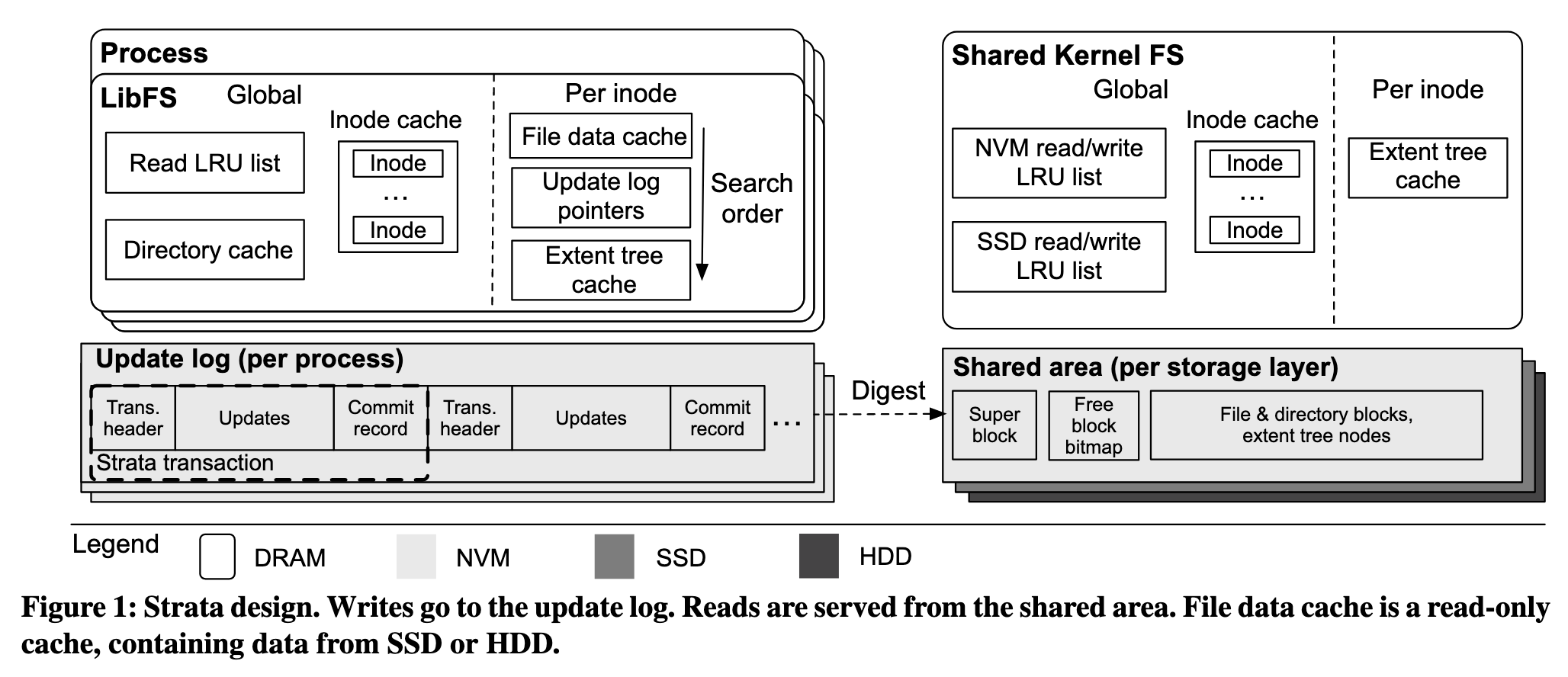
为了减少内核中介的开销,如上文所言,Strata 将文件系统的职责在用户态和内核态之间进行了拆分,划分为用户态的 LibFS 和内核态的 KernelFS。
LibFS: Update Log
LibFS 层面为每个线程设计用户态的私有的 NVM Update
log。对于写操作,LibFS 将写入操作和数据同步地记录在 NVM 中的 Update log
中。由于 NVM 支持字节寻址,可以直接通过 MMU 把 NVM 物理页映射到 LibFS
虚拟地址空间,从而绕过内核,实现零拷贝。由于 Update log 在 NVM
中,这意味着写入是直接同步可持久化的,而传统的 write
通常是先写入易失性的 DRAM 缓存就直接返回(write 的持久化是异步的),在
fsync() 被显示调用时写回脏页。Strata
的这一同步可持久化特性满足了现代 RPC
应用在响应前必须已经快速持久化了数据的需求,尤其能够降低大量 small write
的延迟。
与 NOVA 相比,NOVA 的 Inode log 是真正的数据形式,而 Strata 的 Update log 是等待被 KernelFS 通过 Digesting 操作消费掉的中间形式。之所以要有这个中间形式,是为了大量 small write 的低延迟以及高效的崩溃一致性。
KernelFS: Shared Area
Strata 是一种跨介质的文件系统,提供了统一的接口管理不同的存储介质。 Update log 在达到一定大小后会由 KernelFS 异步地 Digest 到 Shared Area,形成实际的、读优化形式(Read-optimized)的文件数据。KernelFS 合并日志中的操作,将随机访问合并为顺序写入。由于 Digesting 是异步的,所以 KernelFS 可以批量处理 Strata 事务。(如果是同步的,那只有到一个事务处理完一个事务然后才能接下一个事务)
NVM/SSD/HDD 分别有各自的 Shared Area,文件数据块和 Inode 数据块根据热度存放在不同层次结构,充分利用了不同层次结构的速度/容量特点和时间局部性。
Shared Area 对用户态 LibFS 是可读且只读的,可读是为了 LibFS 能快速读取数据,只读是防止多线程写冲突。NVM 中的 Shared Area 会进行页对齐,从而利用 MMU 的页级别访问控制权限。 SSD 的 Kernel Bypass 安全控制是利用硬件功能如 NVMe Namespace,HDD 则是软件模拟。
Shared Area 保留了传统文件系统的 Superblock、Bitmap、Inode、Blocks ,但是提出了一定的优化:
- 传统的文件系统分配空闲块需要获取 Bitmap 锁并且扫描空闲位,造成对
Bitmap 的竞争。而 Strata 的 Free block bitmap 一次抓取一个 Erasure Block
的大小(与 SSD 有关,包含多个空闲块),在这个 EB
中为每个请求顺序地分配空闲块。当 KernelFS
的多个线程同时申请空闲块,他们并不会申请这个 EB
的整体锁,而是用无锁操作抢到
[offset, offset+N)的一系列空闲块,没抢到的继续无锁重试。由于每个线程拿到的都是不同的空闲块位置,所以直接翻转对应 bit 就好,无需加锁。当offset超出了一个 EB 大小,就从空闲池中找一个新的 EB。当一个 EB 中的空间都被回收,则这个 EB 本身进入空闲池等待下一次被复用。 - Strata 将 Inode 当做一个普通的 File,使得 Strata 可以支持热点文件的 Inode 存在于较快存储器层次的 Shared Area 上。由于 Inode 本身也是一个 File,找这个 File 需要找这个 Inode File 的 Inode,但是这个 Inode of Inode File 也需要找 Inode File。为避免 Inode File 本身的 Inode 只存在于 Inode File 上, Inode File 本身的 Inode 被硬编码存放在 Superblock 中。
- Strata 会为文件数据块和 Inode 块建立 Extent Tree 索引,每一存储层次的 Shared Area 都有自己的 Extent Tree Root,NVM/SSD/HDD 共三个 Root。
三 Strata 实现机制
读写操作
对于读操作,LibFS 会先在 DRAM 中的 File data cache 寻找,若 cache miss 则查看 Update log pointer。Update log pointer 记录了每个文件上一次被更改的位置,从而使得“先写了一点然后读取”的操作更简短迅速。若 Update log pointer 中也不存在,则依次查找每个 layer 的 Extent Tree,同时更新缓存。
对于写操作,则是上述 LibFS 获取租约、记录 Update log 到 KernelFS 启动 Digest,Free block bitmap 分配空闲块并更新 Extent Tree 索引的过程。
Strata 事务
LibFS 的持久化单元是事务(Transaction)。Strata 事务提供 ACID 语义,对最大达到 Update log 大小的写入提供原子化保障。若写入数据过多,则拆分为多个 Strata 事务。一个 Strata 事务包括:Header, Update log, Commit Record.
执行(或者说记录) Strata 事务时,先使用 CAS 操作分配 log 空间,写入 Header 和 Update log,等写入持久化完毕后最后持久化写入 Commit Record. 以 Commit Record 结尾的日志才算有效。事务 log 头部包含指向下一个事务 log 的指针,所以 Strata LibFS 的 Update log 实际上是一个事务的链表。
对比 NOVA 的 log 链表,NOVA 的 log 是每个文件的 Inode 里都有一个针对本文件的 4KB 页日志链表,修改或恢复时不冲突;而 Strata 是对所有文件更新事务的链表,需要异步 Digesting 操作来把它们改为读优化的 Blocks + Extent Tree 视图。
租约机制
当两个线程都想写一个文件时,Strata 设计了租约机制(Lease)。租约的语义类似于读写锁,但略有不同。相似点在于,当一个线程试图读写一个文件时,若当前文件没有被其他线程持有租约则直接获取到租约(获取租约的线程可以不经过内核就对该文件进行可持久化写入,即 Update log),其他线程再想写入这个文件不能直接写入,但多个线程可共享读取租约;区别点在于,当线程想写入一个已被其他线程持有租约的文件,必须通知那个线程(在本论文中是 Socket 实现),当前持有租约的线程收到解约通知后会触发 KernelFS Digesting,待 Update log 全部被 Digest 后,原线程正式解约,新线程获取到这个文件的租约。同时,若原线程超时,也会被直接解约,由于 LibFS 的 Update log 通过 Strata 事务保证 ACID 语义,Strata 可以在必要时因租约而撤销任何进行中的读写操作。
传统的锁是锁临界区,每次 write 都需要加锁解锁,如果有 1000 次连续的 write,就需要 1000 次获取锁和释放锁。租约是锁对象(文件)所有权,只要这 1000 次都是同一线程 write,那就只有一次租约申请。二者区别在于何时获取和何时释放,至于读共享写互斥的语义是一样的。
租约机制仍然存在性能瓶颈,但这基于 Strata 认为大部分文件不会被共享访问的设计哲学。
数据转移
Strata 同时管理 NVM/SSD/HDD 三层的 Shared Area,KernelFS 会根据 LibFS 提供 LRU 信息以根据热度决定哪些数据被放在哪一个层次上,即热度更高的数据放在更快的存储层级上。同时,一个 layer 达到 95% 的容量后就会触发 KernelFS 将其 Digest 到下一层级。对于 SSD 而言,KernelFS 采用 Erasure Block 的大小迁移数据以达到最大效率。
四 性能评估
测试环境上,NVM 依然是模拟的。论文作者在 DRAM 上用软件增加延迟并限制带宽(NVM 比 DRAM 慢),其他层次采用 Intel 750 PCIe SSD 和 Seagate 1TB HDD. 对比对象选取了 NVM 层的 EXT4-DAX, PMFS, 以及上一篇读的 NOVA, SSD 层的 F2FS, HDD 层的 EXT4.
Microbenchmark
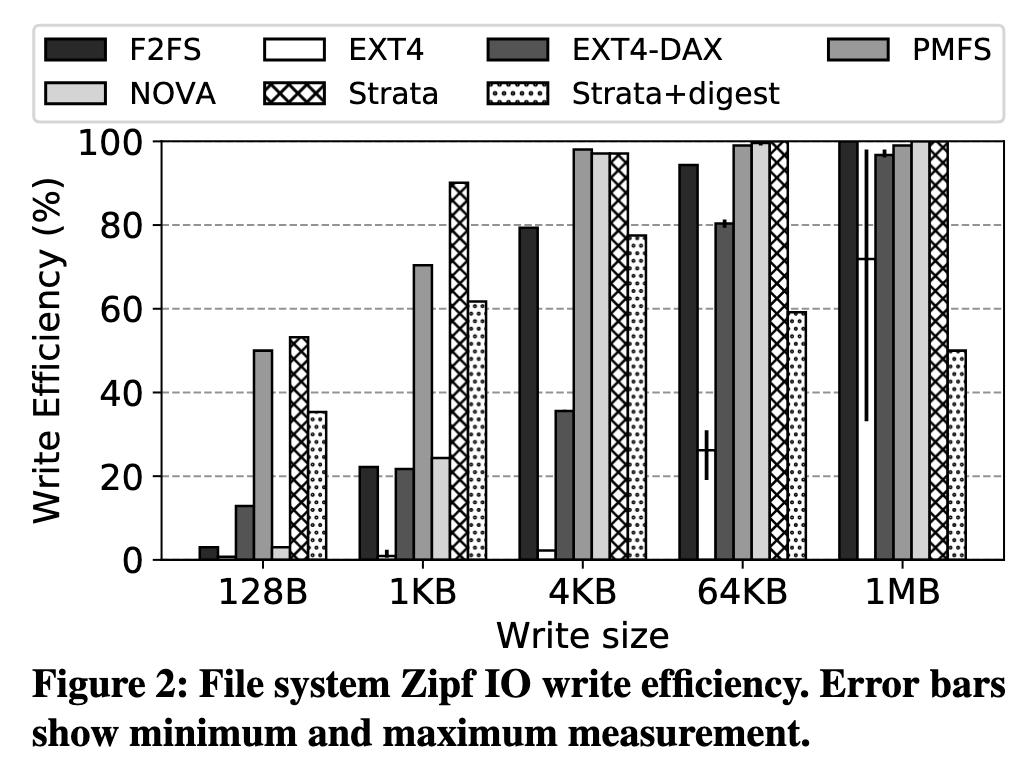
Zipfian 分布的随机写入(一小部分热点被反复写,占比越大的部分写入越少,符合实际需求场景),比较写入效率(写放大的倒数),在较小数据规模下,Strata 的写放大极小,因为这种大量 small write 正是 LibFS Update log 用武之地
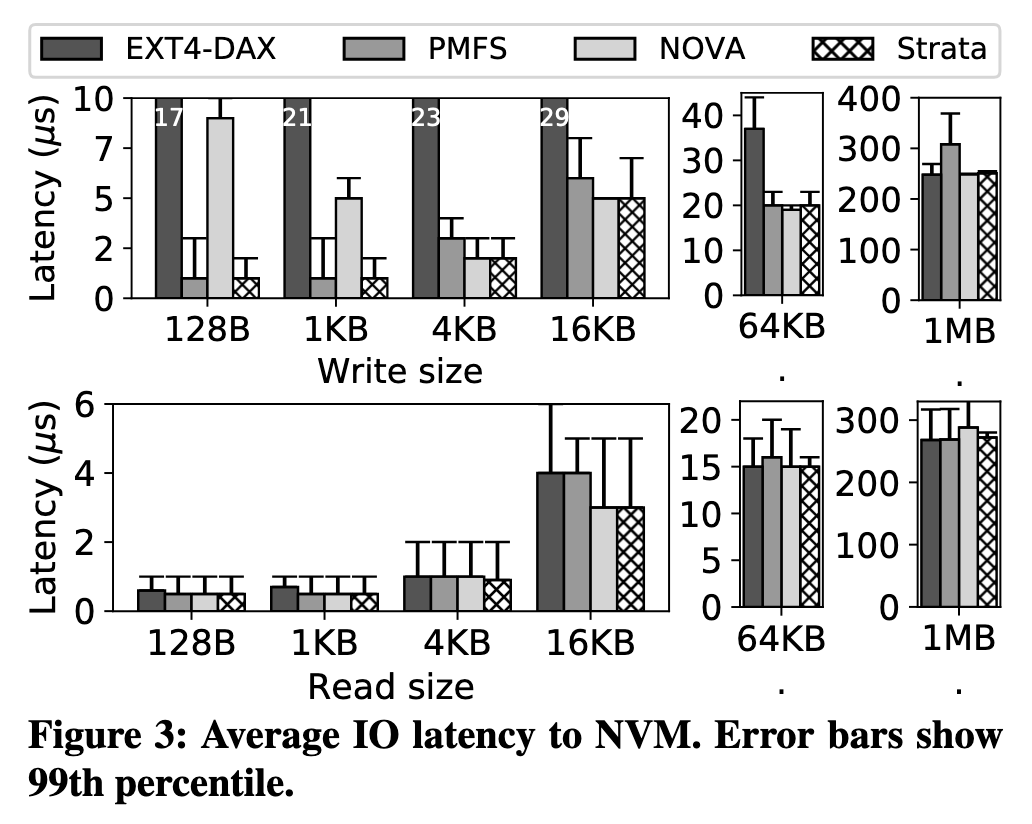
NVM 上的平均 IO 延迟,依然是在 small write 上有优势,因为 LibFS 的部分是零拷贝的,Digest 是后台任务。其他情况大部分持平。Error Bar 代表的是 P99 Latency,Strata 的稳定性也优于对比对象。
NVM 多线程吞吐量扩展性测试,在随机写的情况下 8 线程时 Strata 的吞吐量比 NOVA 高出 28%(这个图太难绷了,看着都在 2.0 附近,但其实其一单位是 GB/s, 其二这个图的纵轴比例很有误导性,实际上确实有 28% 的吞吐量提升,我不知道为什么图 2 为什么还守着那个 0 2 5 7 的纵轴,就为了塞个图例进去吗),但看上去 NOVA 的 throughput scalability 要更线性更好一些。毕竟 NOVA 是 per-inode 的锁,粒度比较小,并发性很好。不过 NVM 本来也比较快,依然拉不开差距。
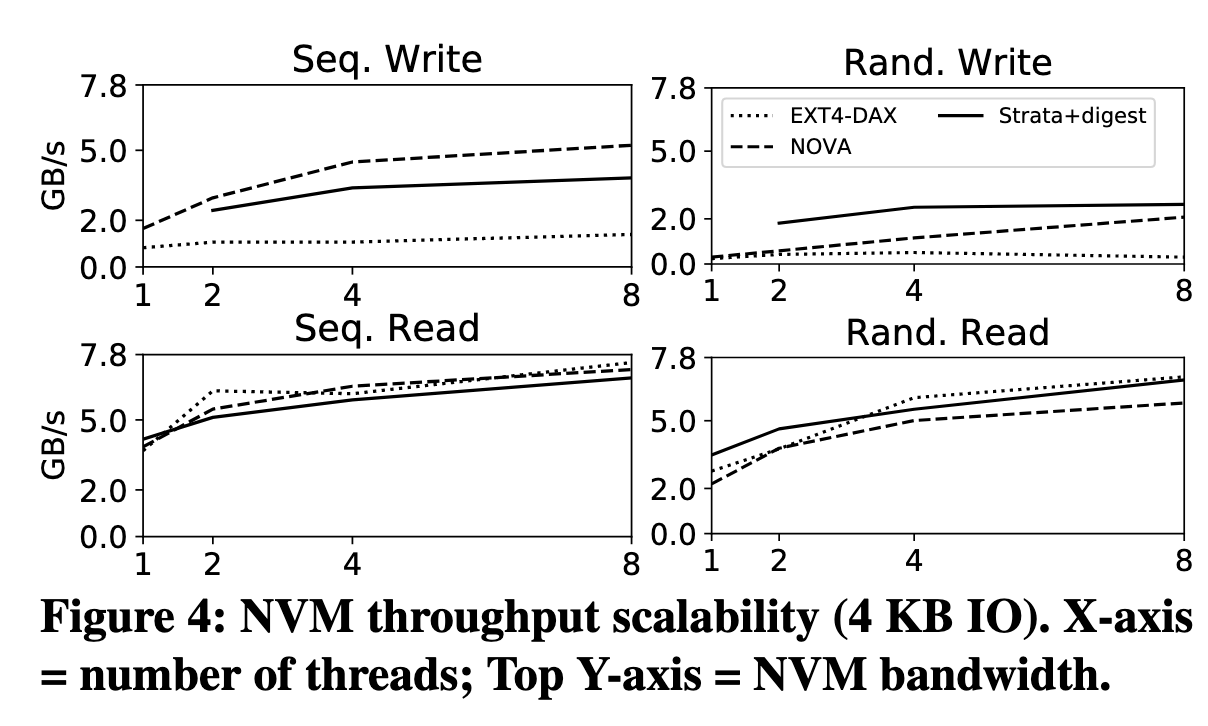
SSD 多线程吞吐量扩展性测试。在写入场景下 Strata 无疑最出色,几乎是顶着 SSD 带宽来的,通过 log 把随机写转换为顺序写非常成功。但是读操作表现比较一般。随机读的那张图没什么意义,因为这里测的 Strata 是单线程的。其实我觉得有一点“懒加载”写操作,把写操作的负载均摊一些到读上了
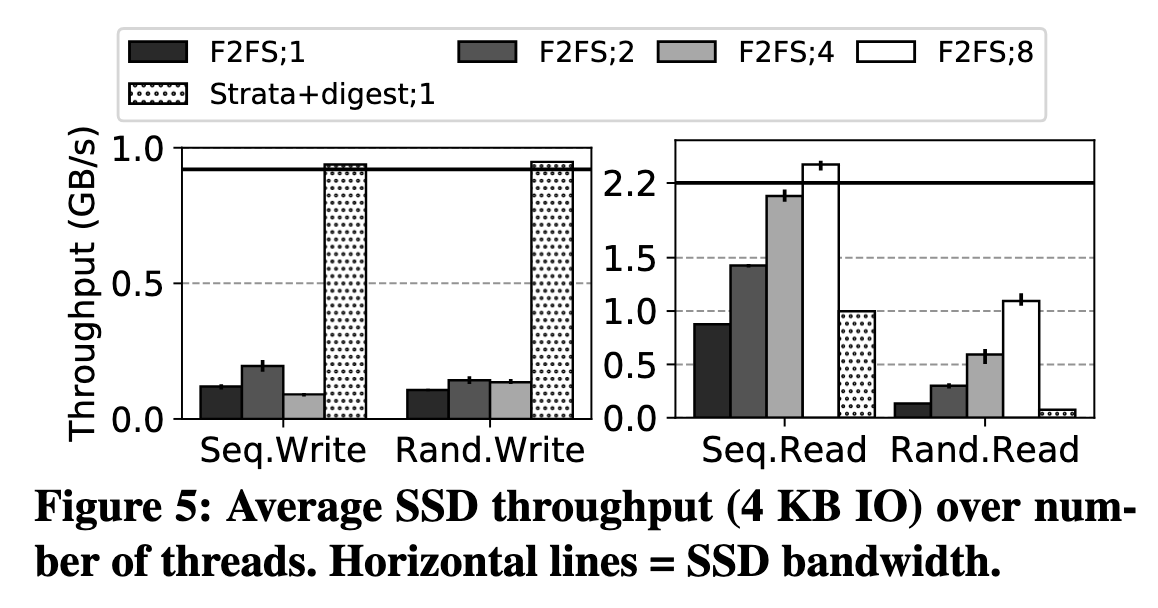
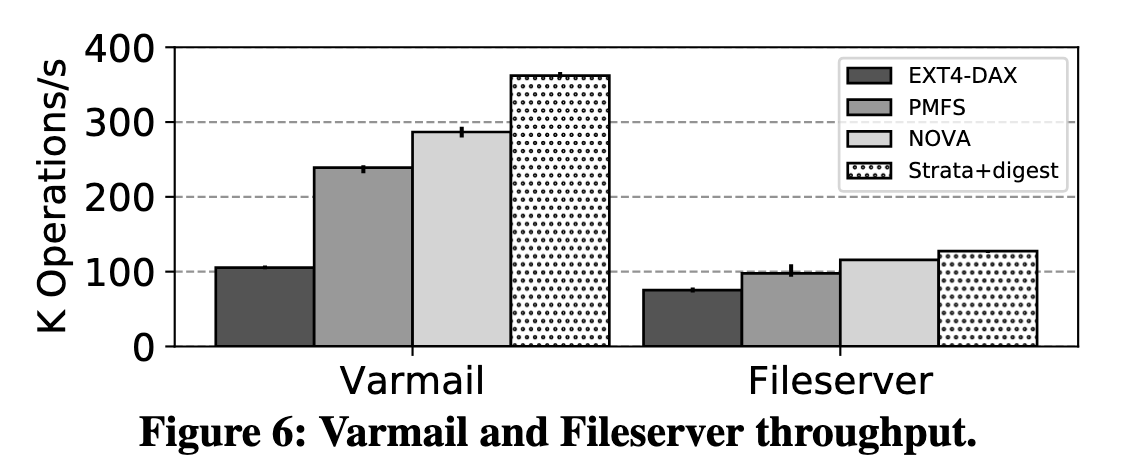
Macrobenchmark
宏基准测试成绩比微基准测试好很多,在 Varmail, Fileserver 上吞吐量领先。邮件服务器产生临时文件,先创建后删除,这些临时文件产生的 log 都在 NVM 的 Update log 里被抵消了,无需 Digest.
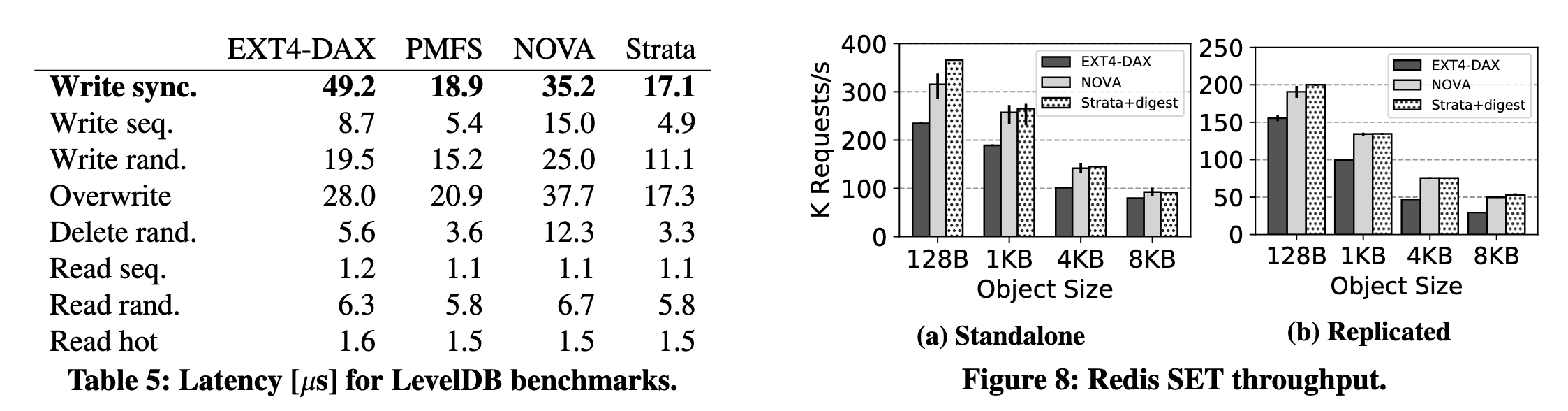
在 LevelDB Benchmark 的写操作上 Strata
也领先(尤其在数据较小时),主要是同步 write 带来的好处,不用每次都
fsync()
在 Redis SET 测试上吞吐量领先但差距不大。
五 阅读总结
看力竭了,比 NOVA 复杂很多,很多机制的意义和目的要想一会才能明白,不像 NOVA 那样很明显就能联系起来。